インタラクティブ・ブローカーズ・ホーム
世界の金融市場
へアクセス
インタラクティブ・ブローカーズ証券株式会社
金融商品取引業: 関東財務局 (金商) 第187号
商品先物取引業 (外国商品市場取引 (委託の媒介)): 農林水産省指令4新食第2087号、20221201商第7号
加入協会: 日本証券業協会、日本商品先物取引協会


プロフェッショナルな価格設定
発注手数料、プラットフォーム利用料なしの低水準な取引手数料

グローバルアクセス
世界の株式、オプション、先物、CFD(差金決済取引)へ、1つの取引ツールから投資可能

最先端テクノロジー
IBKRの強力なテクノロジーが、お客様の取引スピードと効率性の向上、高度なポートフォリオ分析をサポート
強固な財務基盤・顧客資産保全
お客様の全資産を日次で時価評価。IBグループの強固な財務基盤に支えられた資産保全。
IBグループ 取引ツール及びサービス受賞歴
インタラクティブ・ブローカーズ証券株式会社は、インタラクティブ・ブローカーズ・グループの子会社です。

プロフェッショナル・トレーディングの部門で第1位
インターナショナル・トレーディングの部門で第1位

アドバンス・トレーダー部門で
ベスト・オンライン・ブローカー

ベスト・オンライン・ブローカー部門において5つ星の第1位

アドバンス
トレーダー部門でベスト

ベスト・オンライン・ブローカー

プロ向けの価格設定で取引
- 低い取引手数料、利用料なしの取引プラットフォーム
- 当社のBestXTMは、市場への影響を最小限に抑えながら、最良執行の達成と価格向上の最大化を図るようにデザインされた、パワフルで高度な取引テクノロジーです。
- 取引量・取引額に応じた段階的(Tiered)手数料体系
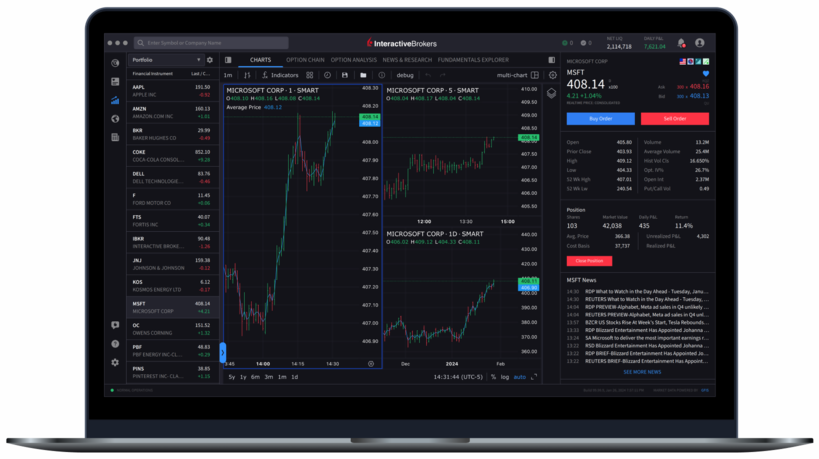
プロも驚く高機能
を備えた取引ツール
IBグループで受賞歴のある取引ツールをデスクトップ、モバイル、ウェブバージョンでご利用いただけます。
指値注文から複雑なアルゴリズム取引まで、充実した注文タイプがお客様の取引ストラテジーをサポートします。
信用できる証券会社
お客様の資金を証券会社に預け入れる際は、その会社が安全で、金融市場の好不況に左右されない耐久力をもっていることを確認する必要があります。当社は、その強固な資本基盤と財務状態、自動化されたリスク管理体制により、万が一金融機関の安定性を脅かす重大な事態が市場で起こっても、グループ全体が守られるように設計されています。
インタラクティブ・ブローカーズ証券株式会社は、インタラクティブ・ブローカーズ・グループの子会社です。
Nasdaq上場:IBKR
S&P 500
構成銘柄
205億ドル
自己資本*
74.6%
非上場(個人所有)
株式比率*
133億ドル
自己資本余力*
312万
お客様口座数*
362万
1日の平均取引数*
IBKRの資産保全体制

*インタラクティブ・ブローカーズ・グループおよびその関連会社の情報を含みます。追加情報に関しましては、「IR情報」-「Earnings Release」の項目をご覧ください。
ご自身にあった口座タイプをお選びください
 個人口座
個人口座 プロップ・ファーム取引口座
プロップ・ファーム取引口座 事業法人口座
事業法人口座 エンプロイー・トラック口座
エンプロイー・トラック口座 機関投資家口座
機関投資家口座ステップ1
口座開設のお申込み
所要時間は数分です。
ステップ 2
口座への入金
銀行口座とリンクまたは
口座移管
ステップ3
取引の開始
投資を次のレベルへ
ステップアップ
- インタラクティブ・ブローカーズ・グループおよびその関連会社の情報を含みます。詳細はこちらより、IR情報内の「Earnings Release」の項目をご確認ください。
- 「インタラクティブ・ブローカーズ・グループ」および「IBKR」には、グループ内すべての子会社が含まれます。